
深度分析
DVM-HALL 與 NHAS:AI 代理人如何重新定義品牌忠誠與機器顧客
隨著 AI 從推薦系統演進為能自主執行購買的代理人,傳統消費忠誠度模型已失效。研究提出 DVM-HALL 模型,透過整合人類情感、機器效用與可驗證執行力來定義品牌選擇,並引入 NHAS 指標量化人機對齊程度。該框架將 DeFi 執行風險納入考量,為企業在面對自主 AI 代理人接管消費決策的「機器顧客」時代提供關鍵的商業對策與治理路徑。
深度分析
隨著 AI 從推薦系統演進為能自主執行購買的代理人,傳統消費忠誠度模型已失效。研究提出 DVM-HALL 模型,透過整合人類情感、機器效用與可驗證執行力來定義品牌選擇,並引入 NHAS 指標量化人機對齊程度。該框架將 DeFi 執行風險納入考量,為企業在面對自主 AI 代理人接管消費決策的「機器顧客」時代提供關鍵的商業對策與治理路徑。

深度分析
LLM 級聯驗證旨在透過多次檢查提升答案可靠度,但現有理論常假設每次驗證獨立。本研究指出驗證器與生成器常有共同盲點,導致可靠度提升由指數級轉為多項式衰減,且存在無法逾越的正確率天花板。研究證明單純增加驗證門檻效果有限,開發者應透過異質化模型或外部工具來降低相關性,才能有效提升 AI 系統的最終精準度。
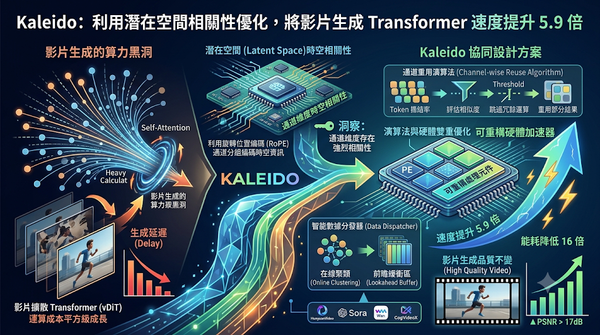
深度分析
面對影片擴散 Transformer 因計算量龐大而導致的生成延遲,研究團隊推出 Kaleido 協同設計方案。該技術利用潛在空間中通道維度的時空相關性,開發通道重用演算法以跳過冗餘運算,並搭配可重構處理元件與數據分發器來優化硬體利用率。實驗證明 Kaleido 可將速度提升 5.9 倍並降低能耗,且維持高水準的影片生成品質。
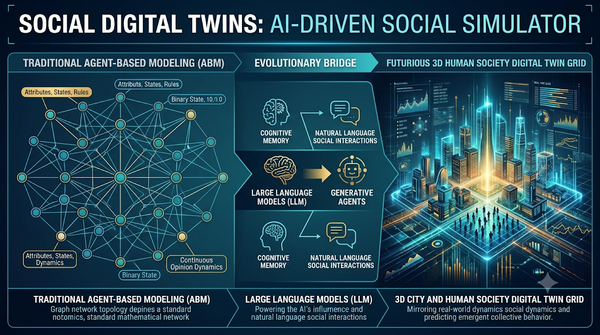
深度分析
社會模擬旨在透過計算方法研究個體間的互動與集體行為。研究從傳統的代理人基模型出發,定義代理人的屬性、狀態與規則,並在網路結構中模擬個體互動。隨後演進至由大語言模型驅動的生成式代理人,進而發展出能鏡像現實世界社會系統的社會數位分身。此演進路徑將社會科學的理論實驗轉化為可量化、可預測的數據驅動框架,大幅提升了對複雜社會動態的分析能力。

深度分析
文件解析長期依賴多階段管線方案,但容易產生錯誤累積。OvisOCR2 推出端到端架構,利用結合真實與合成數據的引擎,搭配 SFT 與強化學習及策略蒸餾技術,將文件影像直接轉換為 Markdown。該模型在 OmniDocBench v1.6 取得 96.58 分的頂尖成績,證明輕量級端到端模型能超越複雜的管線方案,提升解析準確度。

深度分析
現有文字轉音訊模型雖音質優異,但常無法精準遵循多事件與時間順序指令。本研究提出 AJPO 框架,利用音訊感知大語言模型作為評判員,針對聲音事件完整度與時間順序提供細粒度回饋,並透過直接偏好最佳化提升模型表現。實驗結果顯示,該方法能有效改善生成音訊的事件完整性與時間正確性,並推出 S3Bench 基準測試以強化評估。

深度分析
在AI文本偵測競賽中,研究者提出跨世紀語域與現代主義意識流兩種結構性OOD攻擊,能在對抗微調偵測器下仍保持高偽裝率,實驗顯示傳統增添歷史文本的防禦無效,揭示偵測模型在分布外移動時的持續脆弱。研究比較了四大生成模型以及五種策略,並在ELOQUENT2026Voight‑Kampff排行榜奪得前五名。

速報
近期生成式與具身人工智慧的突破,多仰賴大規模多模態預測學習,但仍以被動訓練為主,語言規則作為資訊骨架。神經科學與認知科學則指出,生物智慧的語意結構是由與環境互動形成的具體世界模型支撐,語言才附著其上。

深度分析
隨著深偽技術快速演進,偵測模型面臨性能衰退問題。研究提出BitMindForensics,利用開放式激勵機制讓生成者與偵測者同步競賽,持續刷新訓練資料。實驗顯示其在多項公開基準上達到0.9以上AUC,並在時間序列測試中隨快照更新提升偵測力,預示未來偵測服務將更依賴動態資料流與經濟驅動的自適應流程。

速報
在標記資料稀缺的安全等領域,如何讓大型語言模型在少量樣本下仍具備學習能力是關鍵挑戰。研究提出「注意力頭重新加權 (Attention Head Reweighting, AHR)」方法,只為每個注意力頭學習一個標量,藉此大幅降低需調整的參數量,僅佔模型參數的約 0.0001%。

深度分析
本研究聚焦長上下文大型語言模型的 KV 快取淘汰,指出 H2O 在結構密集的 JSON、XML 等資料中過度保留分隔符與鍵,導致訊號噪聲比惡化。提出基於 SnapKV 的角色條件分配過濾,抑制 KEY 角色提升答案 Token 的保留率,在 5% 預算下恢復超過 60% 的性能缺口,且在較高預算時可匹配或超越完整快取的準確度。
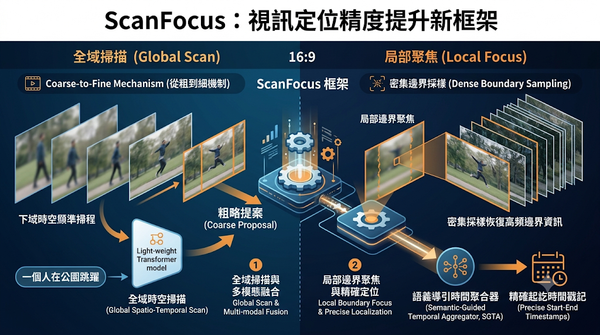
深度分析
時空視訊定位在處理長影片時常因低採樣率而遺失高頻邊界資訊,導致定位不準。ScanFocus 提出一套從粗到細的框架,將任務分為全域掃描與局部聚焦,利用語義導引時間聚合器在邊界周圍進行密集採樣,以恢復被抑制的細節並精確回歸時間戳記。該方法在多個主流基準測試中展現出優於現有 SOTA 模型的偵測精度。