深度分析
「Operator-on-F」揭示世界模型潛在動態誤差:突破價值等價的診斷限制
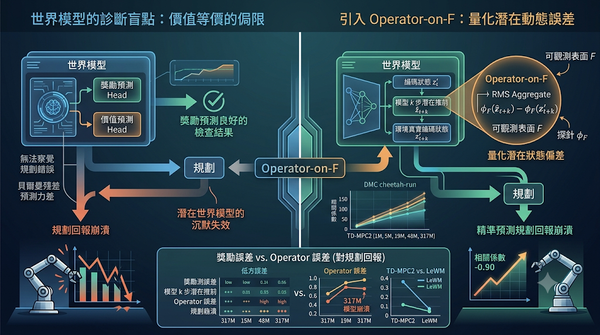
在模型基底強化學習中,傳統的價值等價評估常無法發現影響規劃的潛在錯誤。本研究提出 Operator-on-F 診斷法,透過比對模型 k 步潛在推前與環境真實狀態在可觀測子集上的差異,量化潛在世界模型的動態誤差。實驗證明該指標能有效預測規劃回報的崩潰,補足獎勵預測誤差在模型診斷上的不足。
深度分析
在模型基底強化學習中,傳統的價值等價評估常無法發現影響規劃的潛在錯誤。本研究提出 Operator-on-F 診斷法,透過比對模型 k 步潛在推前與環境真實狀態在可觀測子集上的差異,量化潛在世界模型的動態誤差。實驗證明該指標能有效預測規劃回報的崩潰,補足獎勵預測誤差在模型診斷上的不足。

深度分析
本研究探討在部署大型語言模型時,量化與抽樣溫度對安全對齊的共同影響。透過 9 種指令微調模型、3 種精度與 6 種溫度組合,評估 161 種配置。結果顯示,標準 INT4/INT8 量化對大多數模型安全影響有限,溫度提升才是主要不穩定因素,且兩者互動多為次加性。此結果對未來模型部署策略提供實務指引。
深度分析
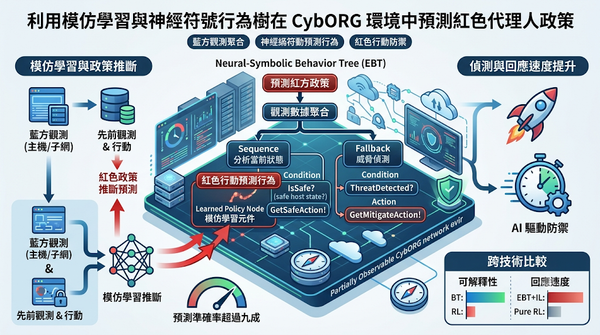
隨著高階網路攻擊頻傳,研究提出以模仿學習於部分可觀測環境中推斷攻擊者政策,結合神經符號行為樹即時預測紅色行動,實驗顯示在多種攻擊策略下預測準確率超過九成。此方法可在藍方觀測到的主機與子網狀態下,利用先前觀測與藍方行動推斷紅方策略,對比傳統僅依賴藍方行為的 RL 模型,提升偵測與回應速度。

深度分析
面對大型語言模型高維嵌入向量導致的存儲與延遲壓力,研究者提出 DIVE 壓縮適配器。該技術透過基於 Hinge 的三元組損失實現梯度自限,避免在數據稀少時過度擾動預訓練空間,並結合多頭 NT-Xent 對比損失提供自監督信號以防止模型崩潰。實驗顯示 DIVE 在多個 BEIR 數據集上性能全面超越現有方案,且能穩定提升檢索品質。

速報
研究以 2020‑2026 年 AI 事故資料庫為基礎,對照 EU AI 法案、NIST 框架與 GDPR 的九項後部署規範,發現 77.1% 事故缺乏監測證據、99.6% 缺乏資料保護影響評估,且 9.8% 同時違反多項規範。內部監測的合規率遠高於外部偵測,顯示監測能力是關鍵。

深度分析
針對作業系統在線調優中缺乏語義理解而導致性能崩潰的問題,研究團隊提出 SemaTune 框架。該技術將 LLM 引入調優迴路,透過快慢路徑雙迴路控制與顯式記憶機制,使系統能理解參數含義並在缺乏應用指標時仍能精準推理。實驗顯示 SemaTune 在 13 種工作負載中性能提升達 153.3%,且能有效避免傳統調優器常陷入的災難性性能下降區域。

深度分析
隨著機器人學習需要大量物理互動資料,傳統人力收集成本高昂。研究提出 RADAR 系統,利用少量 3D 示範結合視覺語言模型與圖神經網路自動產生任務、執行並以 VQA 評估成功,最後以 FSM 完成環境自動重置。實驗顯示在模擬與實機上可達 90% 成功率,顯著提升資料取得效率。

大佬動態
Moonshot AI 今晨推出 Kimi K3,參數約 2.8 兆、上下文長度 1 百萬 token,並承諾於 7 月 27 日開放權重。自報基準顯示在長程知識工作上大幅領先前代,且在多項測試中超過 Claude Opus 4.8 與 GPT‑5.5。此模型有望成為開放式 3 兆級別的首個大型模型,對開發者成本與生態產生深遠影響。
深度分析
隨著大型語言模型被廣泛應用於日常諮詢與道德建議,研究者以 Reddit「Am I the Asshole」的千篇案例,讓 GPT‑4.1、Claude 3.7 Sonnet 與 Gemini 2.0 Flash 以同步與輪流兩種多輪辯論形式共同判定過錯。結果發現,同步模式下 GPT 修正率低於 3%,而 Claude 與 Gemini 超過 28%,且價值取向明顯分歧。辯論格式顯著影響模型的決策慣性與共識形成。

深度分析
面對多代理系統的感知不對稱與層級信念,研究者系統回顧超級遊戲理論,指出階層與圖形模型在欺騙推理上主導,且HNF應用仍少;同時比較RedQueenGodelMachine與參數化開源博弈,顯示超級遊戲在自我演化與合作誘導上具潛力,有望提升安全防護與人機協同。

深度分析
隨著 AI 從推薦系統演進為能自主執行購買的代理人,傳統消費忠誠度模型已失效。研究提出 DVM-HALL 模型,透過整合人類情感、機器效用與可驗證執行力來定義品牌選擇,並引入 NHAS 指標量化人機對齊程度。該框架將 DeFi 執行風險納入考量,為企業在面對自主 AI 代理人接管消費決策的「機器顧客」時代提供關鍵的商業對策與治理路徑。

深度分析
LLM 級聯驗證旨在透過多次檢查提升答案可靠度,但現有理論常假設每次驗證獨立。本研究指出驗證器與生成器常有共同盲點,導致可靠度提升由指數級轉為多項式衰減,且存在無法逾越的正確率天花板。研究證明單純增加驗證門檻效果有限,開發者應透過異質化模型或外部工具來降低相關性,才能有效提升 AI 系統的最終精準度。