深度分析
神經符號架構強化 SLM 推理:Gemma 3 與 Llama 3.2 突破多跳邏輯困境
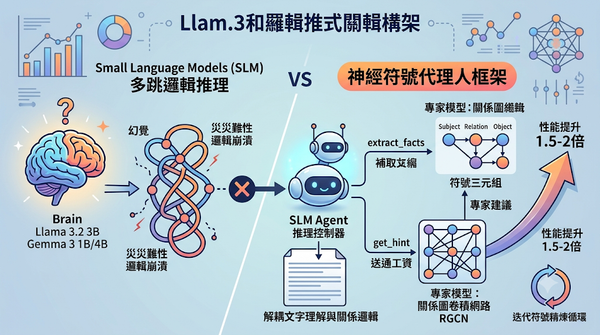
面對大型語言模型部署成本高昂,研究者提出神經符號代理人框架,利用小型語言模型結合關係圖卷積網路(RGCN)來強化其邏輯推理。該方法將 SLM 轉化為代理人,透過提取符號三元組並獲取專家建議來進行多跳推理。實驗結果顯示,此舉能將推理性能提升 1.5 至 2 倍,但同時揭示了資訊提取瓶頸與錯誤累計效應,為低資源環境下的 AI 推理提供了新方向。
深度分析
面對大型語言模型部署成本高昂,研究者提出神經符號代理人框架,利用小型語言模型結合關係圖卷積網路(RGCN)來強化其邏輯推理。該方法將 SLM 轉化為代理人,透過提取符號三元組並獲取專家建議來進行多跳推理。實驗結果顯示,此舉能將推理性能提升 1.5 至 2 倍,但同時揭示了資訊提取瓶頸與錯誤累計效應,為低資源環境下的 AI 推理提供了新方向。

Telegram 機器人
Smart_Group_Bot 是一個基於 LLM 的開源 Telegram 群組管理機器人,採用多層中間件與關鍵字、正則、語意審核三種規則,根據置信度自動執行警告、刪除或封禁。決策模型判斷回應時機,支援多供應商模型回退,提升群組管理自動化與安全性。

深度分析
受人類以語言傳遞空間資訊的啟發,研究團隊提出 Dialogue Place Recognition(DlgPR)概念,將定位問題重新定義為一場互動式對話推理。系統結合跨模態漸進學習檢索器(CMPL)與大型多模態語言模型 DQ‑pilot,透過主動提問逐步釐清模糊描述,並以難度指標與位置檢索增益作為課程學習指導。

LangChain
LangChain 與 Milvus 的新整合套件提供向量儲存、相似度搜尋與混合檢索功能,支援非同步操作與多向量欄位,讓開發者能快速建置語意搜尋與 RAG 應用,提升 AI 系統效能與彈性。此套件同時支援稀疏向量與內建 BM25 檢索,適用於大型語意搜尋與推薦系統。

LLMVault
LLMVault為一套以OWASPLLMTop10(2025)為藍本的開源訓練平台,提供25個分層實驗室,涵蓋提示注入、資料投毒、代理濫用等攻擊向度,讓使用者在本地Docker環境中實作與防禦,提升AI應用的資安意識與實務技能,並支援多種大型語言模型供應商。

Spec Kit ZH
SpecKitZH以中文規格驅動開發為核心,提供Python套件與CLI,支援Codex、Claude Code等AI編碼代理,讓開發者可在數分鐘內完成需求到實作的全流程,提升本地化開發效率。此專案以MIT授權釋出,GitHub累積263顆星,提供安裝指令與上手流程,適合本地化開發團隊導入。

速報
本研究針對搜尋救援任務開發新型三層階層學習架構,結合 Hebbian 可塑性、圖形神經網路強化學習與模型無關元學習,形成反射、技能與推理三層次。架構以二十二項合約提供安全、最佳化等六項保證,並引入群體元認知,使無人機群可自我監控與策略切換,提升任務效能與韌性。

深度分析
目前多鏡頭影片生成常面臨實體特徵漂移問題,導致角色或場景在不同鏡頭間不一致。研究團隊提出 GroundShot 框架,透過建立實體級視覺記憶體並將生成順序與敘事順序解耦,優先生成高品質參考鏡頭以建立標準參考,再將其用於指引引導生成。實驗證明該方法能顯著提升多鏡頭影片的一致性,且無需對模型進行額外訓練或修改。

Wisp Science
隨著 AI-for-Science 趨勢興起,研究人員需要更高效的工具來處理複雜計算。Wisp Science 推出開源且 Local-first 的桌面工作站,整合 Rust 與 Tauri 框架,支援 Python 與 R 的多環境運算,並透過 MCP 協議連結數十個生物資訊資料庫。此專案讓研究者能將 AI 代理技能模組化,顯著提升科學研究的可重複性與開發效率。

Petdex
Petdex是針對Codex、ClaudeCode等AI編碼代理的動畫寵物公gallery、提供CLI一鍵安裝與桌面浮動應用。使用者可透過npx指令快速部署寵物,並在編碼時即時互動,提升開發者的使用體驗與工作環境趣味性。同時支援macOS、Linux與Windows系統。

深度分析
隨著 MoE 模型崛起,訓練成本飆升。NVIDIA NeMo AutoModel 以 Expert Parallelism、DeepEP 與 TransformerEngine 核心,讓微調速度提升 3.4–3.7 倍,GPU 記憶體降低 29–32%。此技術將助力大模型在多節點環境下可行,推動 AI 基礎設施演進。

深度分析
2026年推出的EveryEvalEver(EEE)與HuggingFace社群評估現在可互通,透過單一JSON結構統一報告模型評分,並自動轉換為YAML,提升結果可追蹤性與再現性。此舉填補了評分分散、格式不一的缺口,讓研究者與政策制定者能更快速比對模型安全與效能。