
Meridian
Meridian 開源專案:橋接 Claude Max 訂閱與第三方 AI 編碼工具的代理層
Meridian 是一個開源橋接層,讓 Claude Max 訂閱能在 OpenCode、Aider 等第三方工具中使用。它基於 Claude Agent SDK,不繞過任何限制,僅轉換 API 格式。此專案為開發者提供更多工具選擇,同時尊重 Anthropic 的平台治理。
Meridian
Meridian 是一個開源橋接層,讓 Claude Max 訂閱能在 OpenCode、Aider 等第三方工具中使用。它基於 Claude Agent SDK,不繞過任何限制,僅轉換 API 格式。此專案為開發者提供更多工具選擇,同時尊重 Anthropic 的平台治理。

深度分析
GitHub Explorer 發掘的 Botmux 將飛書橋接至 Claude Code 等 AI 程式設計 CLI,每個會話獨立進程即時串流。不同於 Agent SDK 重構方案,它直接繼承 CLI 完整能力與迭代升級,支援多機器人協作與 Web 終端。此工具可能改變遠端開發協作方式。

CCG-Workflow
隨著 AI 編碼代理普及,單一模型在處理複雜任務時常面臨限制。CCG-Workflow 推出多模型協作引擎,透過單一指令自動分析意圖並編排 Claude、Codex 與 Gemini 協作執行。該工具將不同模型的強項整合至同一工作流,大幅降低開發者在多個 AI 工具間切換的成本,為 AI 驅動的軟體開發提供更高效的自動化協作路徑。

OmniRoute
面對多模型 API 管理的複雜度,開源專案 OmniRoute 提供單一端點連接 271 家供應商,其中 90 余家為免費方案。該工具透過 RTK 與 Caveman 壓縮技術減少 15% 至 95% 的代幣消耗,並內建配額感知自動備援機制。此方案讓開發者能將主流 AI 編碼工具無縫接軌至免費模型,大幅降低開發成本並提升資源利用率。

深度分析
大型語言模型在生成 JSON 等結構化數據時常因機率性質而導致格式錯誤,形成結構鴻溝。研究團隊提出 RL-Struct 框架,透過多維度獎勵函數定義結構層級,並利用 GRPO 演算法在無 Critic 網路的情況下進行輕量化強化學習。結果顯示該方法能顯著提升小型模型的結構準確度與有效性,且模型會自發性地先掌握語法再學習語義。

深度分析
聯網與自動駕駛車輛面臨複雜的軟硬體漏洞威脅,但 CVE 描述多為非結構化文字。研究團隊建構 CAV-STIXGen 資料集,評估多款開源大型語言模型將漏洞描述轉換為 STIX 結構化格式的能力。結果顯示 Phi-4 等模型在實體提取與弱點映射上表現強勁,能有效將漏洞資訊轉化為機器可讀的威脅情報,大幅提升車聯網資安分析效率。

深度分析
強化學習在實作時常面臨模擬環境與現實世界動力學不匹配的挑戰。研究提出 DADiff 框架,將狀態轉移視為生成過程,利用擴散模型的生成軌跡偏差來量化域間差異,並透過修正獎勵函數或篩選數據來優化策略。實驗結果顯示,該方法在處理隨機動力學環境時性能優於現有方案,有效提升了策略的跨域適配能力。
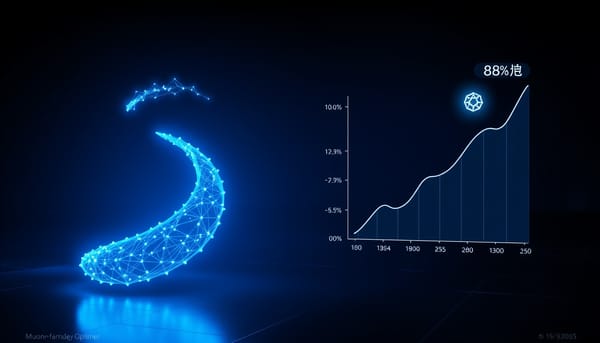
深度分析
研究探討Muon優化器在稀疏回饋的長程代理強化學習中的表現,與AdamW於ALFWorld任務比較。結果顯示,在GiGPO設定下,僅對隱藏矩陣使用Muon可將驗證成功率提升約88%,且在較高學習率仍保持效能。Muon在GRPO與GraphGPO上亦有提升,於GraphGPO接近飽和時差距縮小。

深度分析
研究指出人類視覺需主動觀測,推出 ActiveVision 基準測試大型多模態語言模型的迭代視覺推理能力。實驗發現即使最先進模型也只能正確解答約十分之一,且在多項任務上得分為零;相較之下三位人類受測者平均正確率達九十六點一百分比,顯示目前模型在主動觀測上仍有明顯不足。

深度分析
AI治理正面臨一個關鍵難題:如何在系統更新、環境變動後,持續判斷AI是否仍值得信任?現有方法要不是過於抽象,無法落地到日常監控,就是只專注單一指標,無法與整體治理銜接。本研究提出一套輕量級方法論,包含形式化框架與治理程序兩大部分。

深度分析
隨著社群平台文字與圖片常出現語意衝突,研究提出HCIG層次式跨模態不協調圖網路,分別在詞彙、片語與全局層面建模不一致,並以層次注意力融合。實驗在MMSD與MultiBully上分別達85.74%準確與69.62%準確,顯示階層式圖式推理優於傳統融合。
深度分析
視覺-語言-動作(VLA)模型在機器人操作與控制任務中展現潛力,但後訓練階段因模擬器、機器人型態與任務目標的多樣性而充滿挑戰。現有雲端服務多採單租戶獨佔 GPU 模式,導致短暫或突發性工作負載成本高昂且資源利用率低落。