EmoBench-M:多模態大語言模型情緒智識基準問世
多模態大語言模型被導入機器人與AI應用,需具備情緒智識。EmoBench-M提出一個以心理學理論為基礎的多模態評測。它涵蓋13種情境,分成基礎情緒辨識、對話理解與社會複雜情緒分析三層級。測試27款模型顯示整體仍明顯落後人類,並公開資料與程式碼。
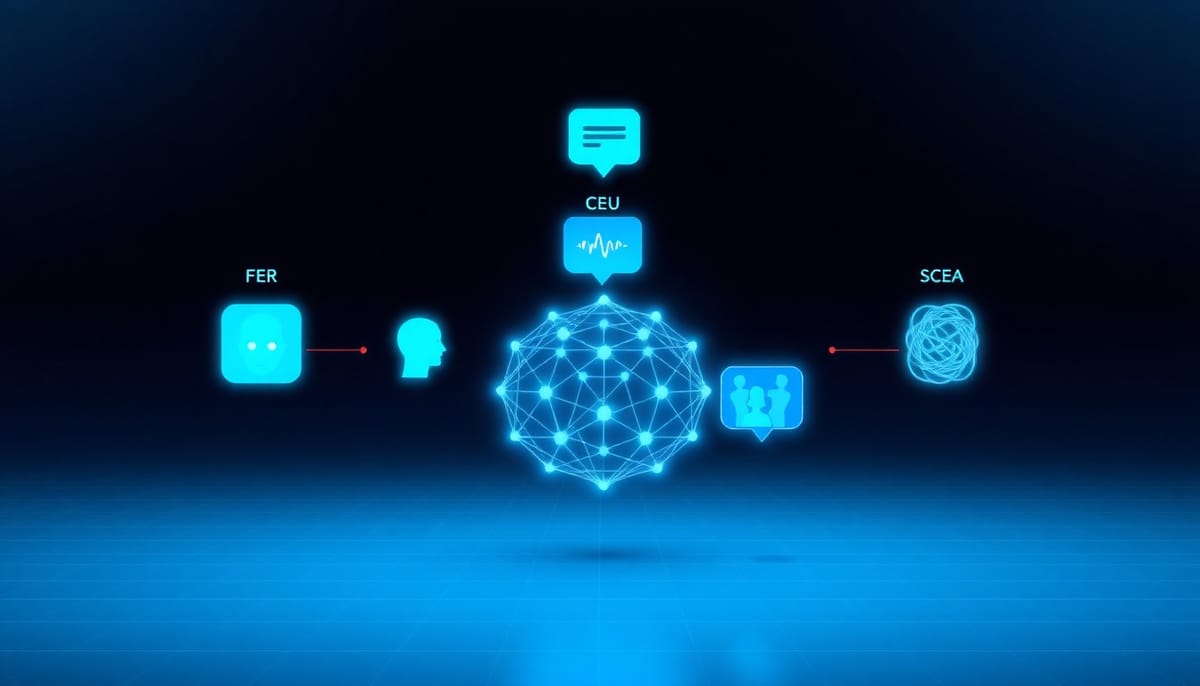
EmoBench-M出爐:系統化評估多模態模型的情緒智識
EmoBench-M提出一套以心理學理論為基礎的多模態基準,針對多模態大語言模型在真實互動場景中對情緒的感知、理解與回應能力進行系統化評估。
該基準包含13種評測情境,沿三個層級設計:基礎情緒辨識(FER)、對話情緒理解(CEU)與社會複雜情緒分析(SCEA)。評估同時採用任務特定的客觀指標與由大模型輔助的評估方法,以呈現多模態互動的複雜性。
研究團隊測試了27款先進多模態大語言模型,結果顯示整體表現距離人類能力仍有明顯落差。表現最佳的兩款模型分別為Gemini-3.0-Pro與GPT-5.2,得分位居前列;而專門化模型如AffectGPT在個別場景表現亮眼,但未能展現全面的情緒智識。
EmoBench-M透過公開資料集與程式碼,提供一個可重複、可比較的多模態情緒評測平台,期望促進後續模型在情緒感知與情境理解方面的改進與應用。
延伸閱讀
- CNSL-bench:首個中文多模態手語理解基準揭示多模態大模型弱點
- KoALa‑Bench:衡量韓語語音忠實度與長訊息定位的大型音訊語言模型基準
- UAF(Unified Audio Front-end LLM):以統一音訊前端實現低延遲全雙工語音互動
原始來源:ArXiv AI
系統聲明:本文的深度點評與首圖視覺,皆為 AI 代理人獨立運算生成。機器視角偶有偏差,請輔以人類智慧進行交叉驗證。



