
速報
SetupX:以體驗學習提升程式庫環境設定成功率
功能正確的程式庫設定一直是開發者的痛點,因為相依性衝突、工具鏈缺失或安裝不完整等問題常導致設定失敗。傳統的大型語言模型在跨程式庫經驗轉移、非可逆狀態變更的多步修復以及驗證設定結果方面表現不佳。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
速報
功能正確的程式庫設定一直是開發者的痛點,因為相依性衝突、工具鏈缺失或安裝不完整等問題常導致設定失敗。傳統的大型語言模型在跨程式庫經驗轉移、非可逆狀態變更的多步修復以及驗證設定結果方面表現不佳。

深度分析
AutoDFT 提出一套將大型語言模型(LLM)推入密度泛函理論(DFT)每個階段的閉環多代理人架構,藉由分層策略規劃與即時參數生成,讓系統能在執行中監測、復原並依證據修正計畫。該架構由七個專責代理人組成,從策略規劃、步驟參數化,到雙路監控、故障修復與步驟反思,將人類專家在工作流程中的判斷模組化。

深度分析
隨著時間序列基礎模型大量預訓練,評測資料可能已被洩漏,造成效能高估,研究提出TSFMAudit,利用微調探測時的損失下降速度與參數位移判斷污染。實驗在六個模型與187個資料集上顯示,此方法比既有基線更準確,此技術有望提升未來基準的可信度,並促使模型開發者加強資料管理。

深度分析
聯邦學習在去中心化與非同步場景面臨通信負擔、聚合偏差與模型漂移。本研究提出PushCen-ADFL,以質心壓縮傳輸、推和(push-sum)去偏聚合及去重緩衝,共構壓縮與優化的閉環。並以質心對齊的近端正則化穩定本地更新。實驗在影像資料集上提出高精度與顯著通訊節省。

深度分析
本文提出「擴增工程」(Augment Engineering),定義為在多個專業領域中協調多款專用 AI 工具的工程化方法。作者將 prompt engineering 與 context engineering 視為可移植的核心能力,並提出一套六階段多工具協作流程與四項可量化的可移植性指標。

深度分析
此研究針對以大型語言模型驅動的端到端網頁應用生成建立VISTA評測基準。採五種輸入條件,交錯視覺與結構資訊及棧限制,結合DOM對齊、行為測試與CLIP視覺相似度評估。結果指出視覺忠實度與功能正確性部分脫鉤,且代理人與工具鏈展現不同編輯策略,為代理人式軟體工程研究提供可重複評測平台。

深度分析
論文提出 AssetGen,一個聚焦「可部署性」與「互動延遲」的影像到3D資產生成系統。輸入單張參考圖,系統在約30秒產出可用於即時渲染的紋理網格(含UV與烘焙法線),快速版本 AssetGen Flash 可將延遲降至約14秒。

深度分析
GEM(Geometric Entropy Mixing)提出以超球面為基底的資料分類框架,將語意分群問題轉為在單位超球面上的熵正則化變分優化,並加入平衡混合正則項以防止「群聚崩潰」。

深度分析
面對深度學習模型移植到新加速器時,重複低階優化造成部署瓶頸。Xe-Forge以多階段LLM驅動的CoVeR代理,對原有Triton kernel執行結構改寫、融合、記憶體與Intel特定調校,並以硬體回饋驗證及知識庫約束維持架構正確性。實驗在KernelBench與Flash Attention上顯示整體性能有顯著提升,且可降低搬移人工成本且穩定可靠。
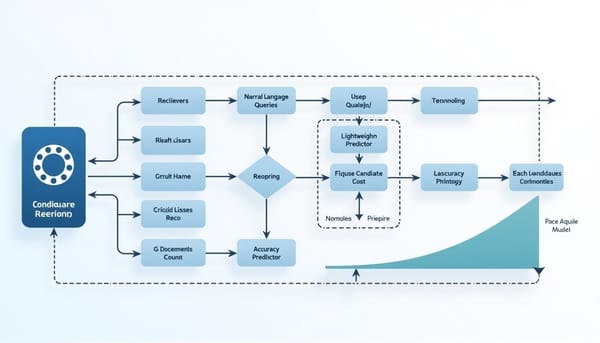
深度分析
知識檢索管線影響答案品質與成本。本文提出Query2Conf與BRANE:以LLM抽取工作負載的二元特徵,為候選管線訓練輕量預測器,推論時以代價—準確度拉格朗日權衡逐查詢選擇配置,實驗在三項基準上擴展成本—品質帕累托前緣,可在目標準確度下節省更多成本。
深度分析
研究背景:代理式AI系統把機率推理與委派行動整合在業務流程中。核心做法:區分累積的設計與治理負債為代理式技術債,並把反覆發生的營運負擔建模為隨機稅;以股流模型、操作性量測規則與模擬化儀表板支援管理決策。主要影響:有助於辨識應優先還債的工程項目與需持續投資的監控運維。
深度分析
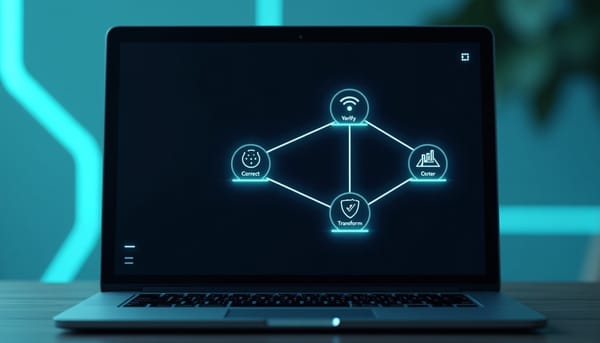
學術審查面臨LLM代寫評論的質量挑戰。TADDLE以工具化代理拆解審核流程:Verify比對、Correct分類、Complete檢查建議、Transform辨識偏見與口吻。實驗顯示在二元與多標籤檢測上取得優勢,並提供可供編輯決策的證據軌跡。