
深度分析
MiRD:透過未覆蓋風險拆解提高開放式問答的可靠集合預測
開放式問答易出現幻覺,MiRD將整體未覆蓋風險拆為有限抽樣失敗與條件篩選失敗。先為抽樣失敗建立期望上界,再於抽樣成功時以全量校準集合校準篩選閾值,實驗顯示可同時控制兩類風險。對比傳統成功條件校準與PAC式界限,MiRD提供更緊的第一階段界限與更具適應性的預測集合。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
深度分析
開放式問答易出現幻覺,MiRD將整體未覆蓋風險拆為有限抽樣失敗與條件篩選失敗。先為抽樣失敗建立期望上界,再於抽樣成功時以全量校準集合校準篩選閾值,實驗顯示可同時控制兩類風險。對比傳統成功條件校準與PAC式界限,MiRD提供更緊的第一階段界限與更具適應性的預測集合。

深度分析
大型 C 程式驗證因狀態爆炸受限,ConVer 以自上而下分解系統斷言,利用大型語言模型自動合約合成,並在 CEGAR‑SMART ICE 迴圈中持續精煉,於四組基準測試中最高達九十六%驗證成功,展示了 AI 輔助形式驗證的可行性,此方法亦為未來 AI 驅動的軟體安全驗證鋪路。

深度分析
結構化資料常用GBDT,兩方垂直分割訓練時識別碼對齊為隱私風險。論文提出匿名訓練,利用雙向circuit-PSI與可編程不可知偽隨機函數實現隱匿ID的逐次聚合。透過將電路PSI輸出作為共享狀態並改良同態加密打包,將部分成本減半。同時實驗顯示效率接近有洩漏的方案。

深度分析
本研究在 Kalai & Vempala 的機率框架上,提出「innovation(創新)」作為衡量模型產生訓練資料外輸出傾向的簡單指標。作者證明創新既由校準條件與缺失質量所蘊含,亦能反向近乎刻畫幻覺現象;換言之,創新與幻覺在該框架下幾乎等價。

深度分析
研究觀察一名醫學研究者在 115 天內嵌入持久化人工智慧代理,系統結合記憶檔案、工具與排程等持久化元素。分析以系統層遙測與 PARE-M 測量框架為主,揭示工作流程以快取為主,產生可量化的治理與審核需求。主要發現提示研究自動化需轉向以產物為單位的成本與可複現性衡量。

深度分析
本研究提出 Kalman Evolve,一套結合參數校準與結構學習的框架,旨在解決當觀測為非線性(例如多普勒雷達、LiDAR)時,傳統卡爾曼過濾器的結構性侷限。方法分兩階段:先估計過程與量測雜訊協方差 Q、R 建立校準基線,再透過大型語言模型輔助的進化搜尋,以語意化程式變異空間作為先驗,發現保有遞迴形式但引入非仿射更新的可解釋演算法。
深度分析
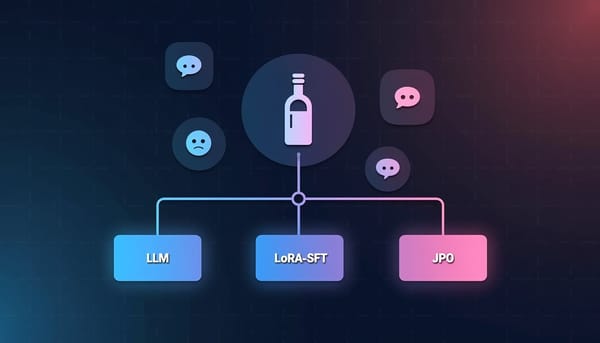
在對抗性談判場景,情緒表達會系統性影響代理人的議價結果。EmoDistill以離線LLM對抗談判軌跡為訓練資料,將情緒分為選擇與表達兩部分,採用隱式Q學習選情緒、LoRA微調學表達並以JPO精煉輸出。實驗顯示小型語言模型能在多個談判領域提升用戶端效用並具備部分跨域泛化能力。

深度分析
近六週來,Trivy 供應鏈攻擊引發的連鎖效應暴露出供應鏈防護的盲點。攻擊者先入侵發佈管道與被盜 CI 憑證,將帶有竊密功能的惡意版本散布至開發者與企業環境,安全廠商 Checkmarx 與 Bitwarden 均受波及。

深度分析
AIGC興起使360°全景生成普及,但任意三維旋轉對浮水印提取構成挑戰。本文以球面調和展開並採用第三階耦合構造,推導出保留相位且嚴格SO(3)旋轉不變的球面雙頻譜,以此在高階頻帶嵌入與從不變標量中回收訊息,實驗顯示對連續旋轉具高度穩健性與視覺保真。

深度分析
在6G網路切片環境中,不同租戶因共用資源而產生的競爭會造成偽因果,阻礙即時攻擊追溯。本文提出DA-GC框架,以資源條件化的Granger因果結合形式化的資源競爭模型,系統性封鎖資源介導之混淆,並以CUSUM分段與Viterbi解碼整合路徑歸因。實驗在15切片測試床中驗證,於87毫秒內達成高準確率。

大型語言模型 (LLM)
一項以Dimensions資料庫為基礎的研究發現,量化學術論文中人工智慧(AI)使用時,若採用混合(pooled)基準,容易將既有寫作風格差異誤認為AI痕跡。研究以人類撰寫與由大型語言模型(LLM)改寫的摘要差異建立AI相似度指標,並比較整體混合基準與按國家與領域分組的基準。
深度分析
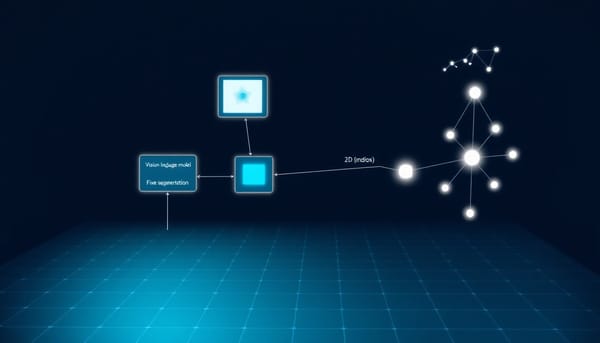
Volumetric Reasoning Segmentation(VRS)在臨床問句下,需把隱含的參照物從語意轉為三維體素級遮罩。MedVol-R1 提出以強化學習驅動的二階段流程:先讓大視覺語言模型(LVLM)回應可驗證的二維證據錨點(關鍵軸向切片與二維邊界框),再由固定的 MedSAM2 將其向跨切片延展成一致的三維遮罩。