
深度分析
NextFund:統一即時績效追蹤平台,全面可視化 LLM 代理人投資決策
隨著大型語言模型開始參與即時投資決策,傳統評估僅看最終報酬缺乏透明度。NextFund透過即時市場接取、跨市場多代理協作與完整決策紀錄,讓模型表現可比、失誤可診斷。實驗顯示平台提升評估公平性與可操作性。平台支援美國、中國與香港股市,並提供互動式交易競技場,讓使用者從排行榜直觀追蹤每筆交易背後的推理。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
深度分析
隨著大型語言模型開始參與即時投資決策,傳統評估僅看最終報酬缺乏透明度。NextFund透過即時市場接取、跨市場多代理協作與完整決策紀錄,讓模型表現可比、失誤可診斷。實驗顯示平台提升評估公平性與可操作性。平台支援美國、中國與香港股市,並提供互動式交易競技場,讓使用者從排行榜直觀追蹤每筆交易背後的推理。

深度分析
隨著具身AI的發展,視覺語言導航系統仍易受視覺擾動影響。研究提出AdvNav以行為導向的黑箱方式,透過雙層粒度回饋與遺傳演化優化擾動,成功干擾多種模型。實驗顯示在R2R測試集上,攻擊成功率最高達87%。此方法不依賴模型梯度,僅利用觀測的行為回饋即可搜尋高效擾動,為評估與強化VLN安全性提供新工具。

深度分析
本篇報導聚焦 QwenPaw-Data,一套針對企業資料分析所設計的代理人系統,將分散於資料倉儲、儀表板、文件與歷史任務的資源,整合成可治理、可演化的分析資產。系統以 DataBridge 提供語意根據、Skill‑Hub 編排分析方法、Host 負責可控的工作流執行,形成語意‑方法‑執行的自我升級迴路。
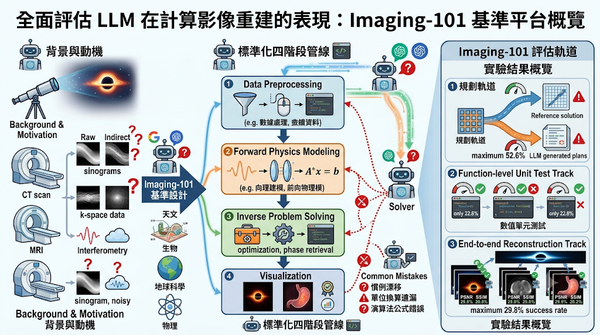
深度分析
Imaging-101 以57項經專家驗證的計算影像任務,將流程標準化為前處理、物理建模、逆向求解與視覺化三階段,評估七大前沿LLM在規劃、單元測試與端到端重建三條軌道的表現,結果顯示模型在物理慣例與演算法選擇上仍有缺口,預示未來需專屬領域代理人才能可靠支援計算影像。
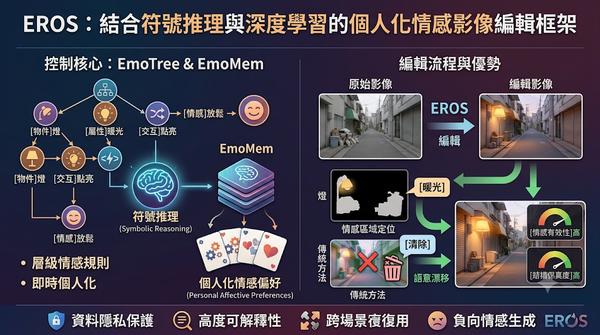
深度分析
本研究針對個人化情感影像編輯提出EROS系統,結合符號推理與深度學習,透過情感規則樹與可擴充記憶庫在推論時即時個人化。實驗顯示其在引發目標情緒與保持畫面結構上優於現有多模態模型。此技術有望推動情感計算、心理健康與自適應媒體的發展。並具備高度可解釋性與資料隱私保護。

深度分析
AI YOU Town 是一個以個人數位雙生(Personal Digital Twin)為核心的互動平台,透過大型語言模型(LLM)結合貝葉斯後驗更新與共形預測,持續校正使用者的 22 維人格輪廓。系統採用三層記憶架構(工作、情節、語意)保存對話證據,使角色在長達百輪的互動中仍能維持一致性,並降低人格漂移。

深度分析
在大型語言模型安全控制的研究中,稀疏自編碼器(SAE)特徵干預被認為能以較少的內部擾動改變行為,然而最新的匹配相干門評估顯示,若不將干預層面與密集基線對齊,所謂的效率優勢往往是比較基線不一致的假象;在同層或投射至SAE解碼器範圍的密集干預下,SAE的優勢甚至會逆轉,且在小模型上常出現單一安全判官的虛假越獄訊號。

深度分析
在海關關稅、出口管制等需遵循嚴格法規的分類任務中,研究提出具約束感知的階層搜尋框架,將法規文件轉為可搜尋樹狀結構,僅檢索合法子節點並以證據片段指導決策。實驗顯示在四項基準資料上提升整體準確度,並提供可解釋的決策路徑,特別在相鄰細分類別與規則邊界條件的案例中提升幅度最大。

深度分析
隨著大型語言模型在多步推理上需求提升,傳統單次檢索已不足。研究提出 GRASP,透過強化學習讓模型在語意搜尋、關鍵字搜尋與段落閱讀間動態切換,僅在需要時擴充上下文。實驗顯示在 HotpotQA、2WikiMultiHopQA 與 MuSiQue 上,其檢索召回與問答正確率均超過現有單步與提示式基線。
深度分析
本研究針對企業 AI 系統的答案復用問題,提出以受治理的商議等價類取代傳統相似度快取的新框架。透過三層等價關係與商議答案分割,確保答案復用在授權與版本控制下具數學嚴謹性。實驗顯示此方法在多輪指令遵循與代理行為任務上提升了跨域泛化與可審計性。此技術亦為未來 AI 合規平台提供基礎。

深度分析
在多媒體圖形資料持續湧入的情境下,UNIT透過首次微調LLM並以不確定感知錨點與結構融合模型,克服語意與拓撲分離與知識不平衡問題,實驗顯示其在五大基準上達到最佳表現。該框架僅在首任務微調LLM,後續任務僅更新分類器,顯著降低計算成本,同時在ACC指標上領先2%至5%不等。

深度分析
隨著AI代理能力提升,失敗變得更微妙,研究團隊推出Who&WhenPro基準,透過自動錯誤注入產生12,326筆跨文字、影像、影片的失敗軌跡,證實即使是大型模型仍在定位與診斷錯誤上有顯著挑戰。該基準涵蓋文字、影像、影片三種模態,且支援單代理與多代理情境,實驗顯示開源模型具成本效益,有望促進自我改進代理系統。