
深度分析
大型語言模型調查模擬平台 Anamnesis:Anthology、Alterity 核心技術與實驗成果
研究以Anamnesis為平台,結合Anthology與Alterity方法,利用大型語言模型生成具敘事背景的虛擬人格,模擬民意調查。平台支援多模態問卷與人口結構控制,實驗顯示其意見分布較傳統人格提示更貼近真實調查結果。平台支援自訂人口分布與多媒體題型,圖形介面可直接建置與分析問卷。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
深度分析
研究以Anamnesis為平台,結合Anthology與Alterity方法,利用大型語言模型生成具敘事背景的虛擬人格,模擬民意調查。平台支援多模態問卷與人口結構控制,實驗顯示其意見分布較傳統人格提示更貼近真實調查結果。平台支援自訂人口分布與多媒體題型,圖形介面可直接建置與分析問卷。
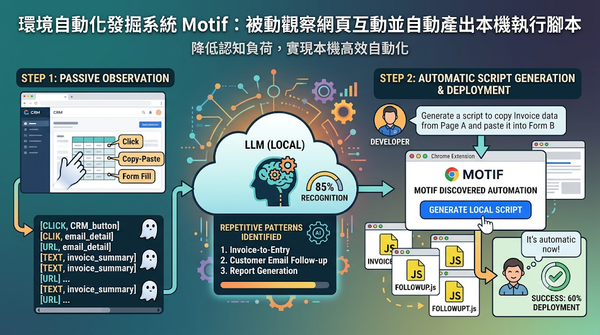
深度分析
隨著大型語言模型協助程式生成,使用者仍需自行判斷哪些工作可自動化。Motif透過被動觀察瀏覽行為,自動找出重複步驟並建議程式,研究顯示八位參與者中有超過八成的模式被認可,且六成成功部署。這些自動化程式在使用者確認後即可本機執行,降低雲端推論成本,並提供持續可調整的腳本。

深度分析
隨著 AI 盜用個人影像問題惡化,研究提出 DiffUE,使用擴散自編碼器在語意空間注入防護噪聲,取代傳統像素層干擾。此方式在保留自然視覺品質的同時,對抗訓練、灰階轉換與壓縮等重訓手段,實驗於 CIFAR、CelebA‑HQ 與 ImageNet 上均顯示顯著提升防護效果,F1 分數下降逾 10%。
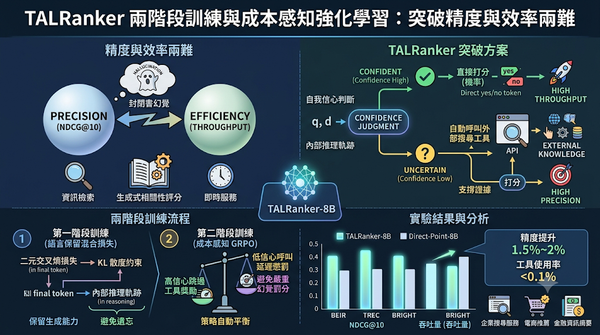
深度分析
隨著使用者需求日益複雜,僅靠參數模型的檢索排序常產生幻覺。TALRanker 以代理式馬可夫決策流程,讓模型在自信時直接打分,不自信時自動呼叫外部搜尋工具。實驗顯示其在多項基準上同時提升精度與吞吐量,此設計亦為企業在即時服務中平衡成本與準確性提供可行參考。

深度分析
針對大型語言模型推理時的激活導向缺乏理論基礎且易導致分佈外性能下降的問題,研究團隊推出 Cobras 框架。該技術將激活導向建模為超球面上的薛定谔橋問題,利用熵最適傳輸導出嚴謹的對數密度比目標,並實現根據查詢動態調整的導向方向。實驗證明 Cobras 在提升模型真實性與去毒化效果的同時,能有效避免分佈外數據的性能崩潰。
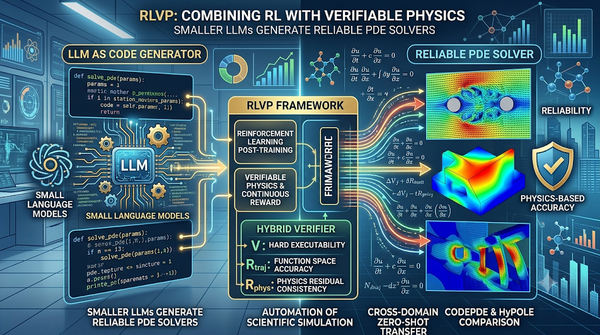
深度分析
傳統偏微分方程(PDE)求解器的開發高度依賴專家經驗,而現有大型語言模型生成程式碼時,往往難以將數值可靠性內化。為此,研究提出 RLVP 框架,透過後訓練將執行結果與物理正確性轉化為連續獎勵(包含可執行性、函數空間精度與物理殘差一致性),引導模型自動生成符合科學規範的 PDE 求解器。 實驗表明,經過 RLVP 訓練的小型語言模型,在分佈內 PDE 生成的表現上超越了前沿模型的提示詞效果,並展現出跨領域的零樣本轉移能力。此研究證實了將可驗證物理回饋納入訓練的可行性,預示著 AI 科學計算未來將朝向「小模型 + 物理驗證後訓練」發展,能大幅降低開發門檻並加速自動化模擬工作流。

深度分析
針對大型語言模型在程式碼異味偵測中容易順從使用者誘導而產生錯誤判斷的討好傾向,研究團隊提出證據導向去偏見提示法 EGDP。該技術要求模型在做出分類決定前,必須先提取程式碼中可觀察的結構指標作為證據,強制執行證據優先的推理流程。實驗結果顯示 EGDP 能將決策翻轉率從 72% 大幅降至 12%,有效提升 AI 程式碼分析的客觀性與穩定性。

深度分析
隨著大型語言模型代理人能自行提出假說、編寫程式並產出圖表,研究流程逐漸自動化。但因每一步皆為隨機 LLM 呼叫,結果不穩定且難以追蹤。本篇提出以資料庫管理系統為藍本,將研究計畫視為可版本化、確定性的資料流,引入版本、回溯與可見化機制,使系統更可靠且不浪費資源。
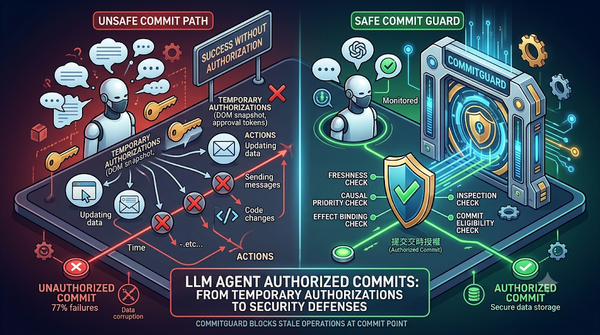
深度分析
LLM代理人在可變環境中常依賴暫時授權,如DOM快照或批准令牌,本文提出提交時授權概念,定義四項邊界檢查,並以54個任務測試,發現即使最終結果看似正確,仍有高比例未授權提交,此現象在瀏覽器、工具與多代理人三大場景皆觀測到,未授權提交比例高達77%。CommitGuard可於提交點阻擋陳舊操作。
深度分析
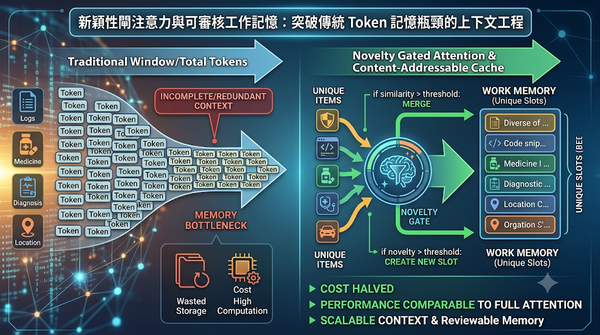
研究聚焦於長串冗餘資訊的上下文管理,提出新穎性閘注意力與內容尋址快取相結合的工作記憶。此機制僅保留獨特項目,將記憶規模與資訊多樣性掛鉤。實驗顯示在多領域資料流上,效能媲美全注意力且成本減半,預示未來 AI 系統可更有效率地處理大規模上下文。相較於傳統窗口或重複刪除策略,它在保持關鍵資訊上更具優勢。
深度分析
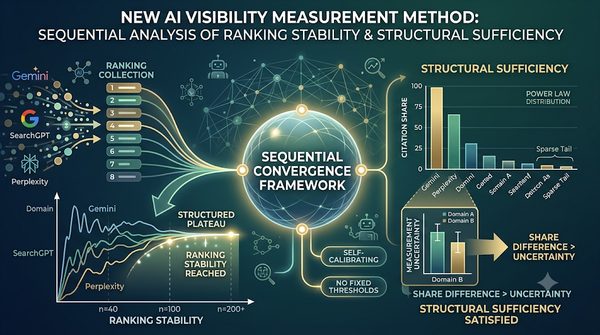
本篇報導探討生成式搜尋引擎的可見度測量,提出以排名穩定性與結構充分性為雙重判準的序列收斂框架。該框架不依賴外部設定的相關係數或信賴區間寬度,而是直接從觀測到的引用分布結構自動校準,決定何時收集的資料足以支撐比較分析。
深度分析
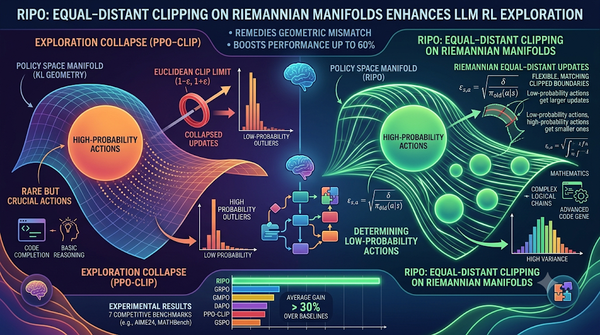
大型語言模型的強化學習常用PPO‑Clip,但因使用歐式度量與策略流形的黎曼幾何不匹配,導致探索崩潰。研究提出Riemannian等距策略優化(RIPO),在流形上等距調整剪裁界限,使低機率動作獲得較大更新,平衡探索與利用。實驗顯示在七項競賽基準上,RIPO相較於GRPO提升最高達60%。