深度分析
CatalogAgent:利用監督者代理人與上下文工程實現電商目錄自我學習
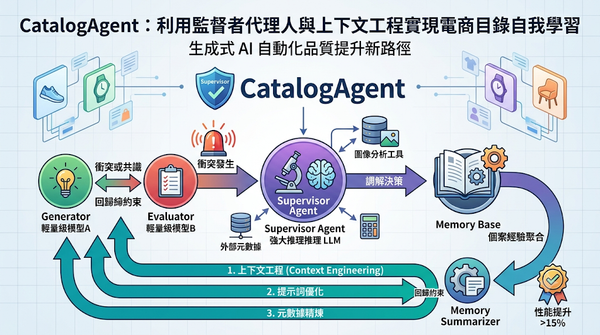
電商產品目錄常面臨屬性值缺失或錯誤的挑戰。研究團隊推出 CatalogAgent 系統,透過監督者代理人調解生成器與評估器的輸出衝突,並將調解經驗存入記憶庫。系統利用記憶總結器將個案經驗轉化為上下文工程指令,回饋給輕量級模型以實現自我學習。實驗證明此機制可顯著提升屬性預測準確率,為生成式 AI 的自動化品質提升提供新路徑。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
深度分析
電商產品目錄常面臨屬性值缺失或錯誤的挑戰。研究團隊推出 CatalogAgent 系統,透過監督者代理人調解生成器與評估器的輸出衝突,並將調解經驗存入記憶庫。系統利用記憶總結器將個案經驗轉化為上下文工程指令,回饋給輕量級模型以實現自我學習。實驗證明此機制可顯著提升屬性預測準確率,為生成式 AI 的自動化品質提升提供新路徑。
深度分析
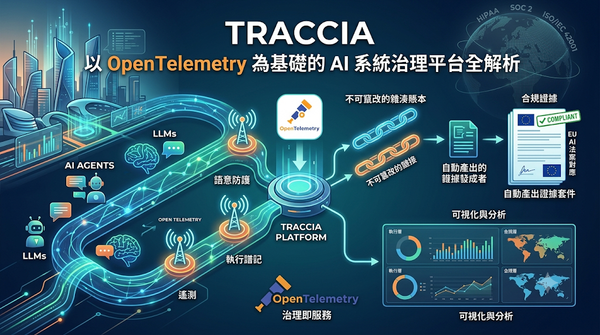
隨著大型語言模型與自主AI代理快速崛起,現有治理工具難以滿足EU AI法案的透明與問責要求。Traccia以OpenTelemetry為基礎,將遙測、語意防護與執行譜記整合至不可竄改的雜湊賬本,自動產出符合多條款的合規證據,縮短治理與合規的最後一哩路。

深度分析
本篇報導深入探討生成模型的控制機制,指出傳統的提示、指導尺度與屬性標籤(統稱旋鈕)只能在資料預先設定的「預算」內調整屬性,而大量未被旋鈕覆蓋的範圍只能透過示例(具體實例)來引導。研究提供了以訓練資料簡易審核預算的方法,並示範在影像與晶體結構兩個完全不同領域中,示例導向如何突破旋鈕的限制,實現更完整的屬性移動與更高的表現力。

速報
研究針對 28 場衝突向五大 AI 問答引擎提出 5,460 個問題,將回覆與已知事實比對。結果顯示,當可查證的資料稀薄時,模型更容易捏造、錯置或錯算資訊,且這類薄弱記錄容易被生成式引擎優化(GEO)操控,成為錯訊與假訊的溫床。分析 1,048 個來源網站後發現,GEO 已在實務中運作,且國家或黨派的數位介入正快速擴散。

速報
現有 AI 研究系統多集中於經驗驅動領域,缺乏對理論推導的支援。ReasFlow 推出端到端自主代理系統,透過內部驗證迴圈確保邏輯一致性,並結合自動化知識檢索與自我提升機制,將文獻合成、定理證明與論文撰寫整合在單一系統中。該系統能從極簡提示詞自主生成完整研究論文,且評分結果優於目前主流開源基準模型。
深度分析
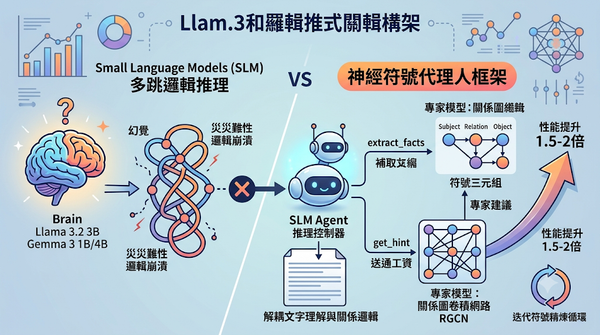
面對大型語言模型部署成本高昂,研究者提出神經符號代理人框架,利用小型語言模型結合關係圖卷積網路(RGCN)來強化其邏輯推理。該方法將 SLM 轉化為代理人,透過提取符號三元組並獲取專家建議來進行多跳推理。實驗結果顯示,此舉能將推理性能提升 1.5 至 2 倍,但同時揭示了資訊提取瓶頸與錯誤累計效應,為低資源環境下的 AI 推理提供了新方向。

Telegram 機器人
Smart_Group_Bot 是一個基於 LLM 的開源 Telegram 群組管理機器人,採用多層中間件與關鍵字、正則、語意審核三種規則,根據置信度自動執行警告、刪除或封禁。決策模型判斷回應時機,支援多供應商模型回退,提升群組管理自動化與安全性。

深度分析
受人類以語言傳遞空間資訊的啟發,研究團隊提出 Dialogue Place Recognition(DlgPR)概念,將定位問題重新定義為一場互動式對話推理。系統結合跨模態漸進學習檢索器(CMPL)與大型多模態語言模型 DQ‑pilot,透過主動提問逐步釐清模糊描述,並以難度指標與位置檢索增益作為課程學習指導。

LangChain
LangChain 與 Milvus 的新整合套件提供向量儲存、相似度搜尋與混合檢索功能,支援非同步操作與多向量欄位,讓開發者能快速建置語意搜尋與 RAG 應用,提升 AI 系統效能與彈性。此套件同時支援稀疏向量與內建 BM25 檢索,適用於大型語意搜尋與推薦系統。

LLMVault
LLMVault為一套以OWASPLLMTop10(2025)為藍本的開源訓練平台,提供25個分層實驗室,涵蓋提示注入、資料投毒、代理濫用等攻擊向度,讓使用者在本地Docker環境中實作與防禦,提升AI應用的資安意識與實務技能,並支援多種大型語言模型供應商。

Spec Kit ZH
SpecKitZH以中文規格驅動開發為核心,提供Python套件與CLI,支援Codex、Claude Code等AI編碼代理,讓開發者可在數分鐘內完成需求到實作的全流程,提升本地化開發效率。此專案以MIT授權釋出,GitHub累積263顆星,提供安裝指令與上手流程,適合本地化開發團隊導入。

速報
本研究針對搜尋救援任務開發新型三層階層學習架構,結合 Hebbian 可塑性、圖形神經網路強化學習與模型無關元學習,形成反射、技能與推理三層次。架構以二十二項合約提供安全、最佳化等六項保證,並引入群體元認知,使無人機群可自我監控與策略切換,提升任務效能與韌性。