深度分析
開源多代理平台 BrainPilot:結合知識庫與 Graph of Trace 實現腦科學全流程自動化
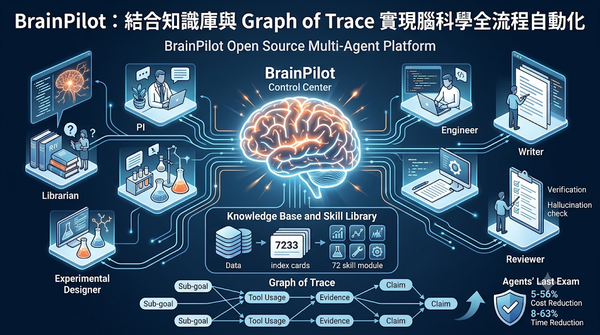
隨著腦科學需整合跨尺度與跨模態證據,BrainPilot以多代理協作、統一知識庫與可追溯圖譜自動化研究流程,並加入審核代理防止捏造,實驗顯示在成本與時間上優於傳統框架,顯著提升研究效率。系統以圖譜記錄每一步驟,支援研究者檢視與驗證,且在公開基準測試中與最先進框架表現相當。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
深度分析
隨著腦科學需整合跨尺度與跨模態證據,BrainPilot以多代理協作、統一知識庫與可追溯圖譜自動化研究流程,並加入審核代理防止捏造,實驗顯示在成本與時間上優於傳統框架,顯著提升研究效率。系統以圖譜記錄每一步驟,支援研究者檢視與驗證,且在公開基準測試中與最先進框架表現相當。

深度分析
針對公共部門AI應用的評估瓶頸,研究團隊推出Kaleidoscope工作流,結合人格化測試生成、可客製化評分規範與人類校正的LLM判官機制,於四項實務案例中驗證可提升自動化評分的可靠性與成本效益。此流程亦支援本地治理決策,未來可延伸至多回合代理人與檢索系統,為AI應用測試提供更完整的閉環改進機制。
深度分析
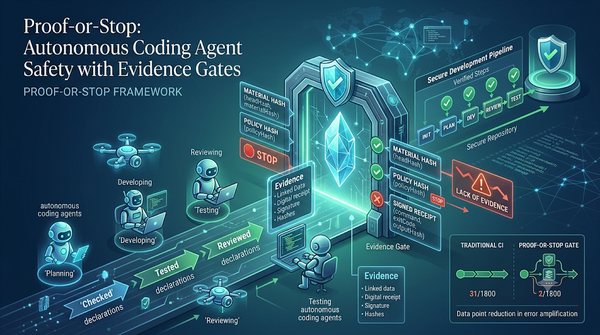
隨著自主程式碼代理日益普及,傳統CI只能提供綠色管線,未能驗證實際證據。Proof‑or‑Stop透過新型證據門控,將每個生命周期聲明綁定最新源碼雜湊與簽章,實驗顯示可將錯誤放大比例從31/1800降至2/1800,提升安全性。此機制同時支援跨供應商協調與持續回饋,為未來全自動化開發流水線奠定基礎。

深度分析
隨著MCP伺服器成為LLM與工具接點的核心基礎設施,現有基準未考慮工具介面持續演化。研究提出MCPEvol‑Bench,模擬11種變異操作在123台伺服器上生成多版本工具集,測試12大模型的適應性。結果顯示即使是前沿模型在演化環境中也會下降近14%,凸顯動態工具環境下的脆弱性。

深度分析
隨著程式碼代理人需處理實務支付整合,Alipay-PIBench以真實Alipay商品與商業庫存,設計Basic與Advanced兩階段情境,結合產品導向任務建構與rubric衍生評估,測試功能正確、可靠與資金安全。實驗顯示六模型在有技能輔助下平均RPR提升10.31百分點,基礎任務改進更顯著。
深度分析
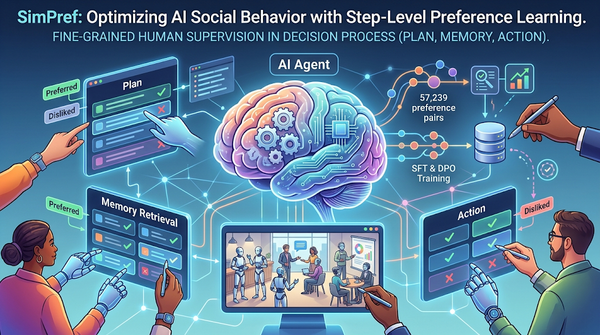
在複雜的社會模擬中,生成式代理人往往缺乏細粒度的行為指導。本研究推出 SimPref 互動介面,讓人類標記員在代理人的規劃、記憶檢索與行動等中間決策步驟中提供即時偏好監督,並建構出包含 5.7 萬組偏好對的資料集。透過 SFT 與 DPO 訓練,開源模型在未知社交情境下的協調能力與行為品質顯著提升,證明步級監督能有效優化長程社交行為。
深度分析
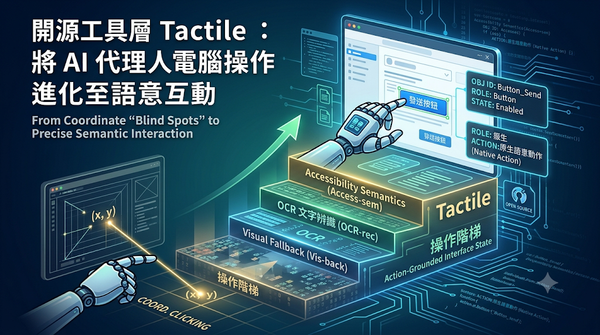
目前 AI 代理人操作電腦多依賴螢幕截圖與座標預測,導致操作過程脆弱且難以驗證。研究團隊推出開源工具層 Tactile,透過整合作業系統輔助功能語意、OCR 與視覺回退機制,將 UI 轉換為可驗證的語意狀態,讓 AI 能直接操作 UI 物件而非盲目點擊座標。在 macOSWorld 測試中,Tactile 顯著提升了多款 AI 代理人的任務成功率,證明了語意化底層對提升 AI 操作可靠度的重要性。
深度分析
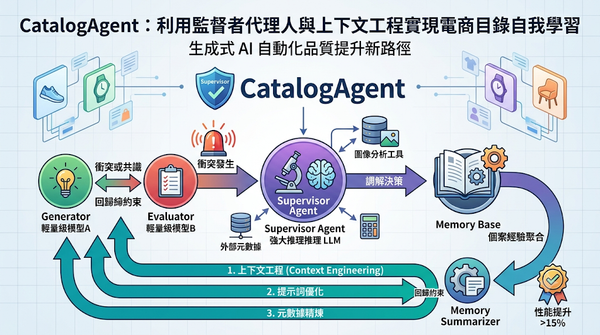
電商產品目錄常面臨屬性值缺失或錯誤的挑戰。研究團隊推出 CatalogAgent 系統,透過監督者代理人調解生成器與評估器的輸出衝突,並將調解經驗存入記憶庫。系統利用記憶總結器將個案經驗轉化為上下文工程指令,回饋給輕量級模型以實現自我學習。實驗證明此機制可顯著提升屬性預測準確率,為生成式 AI 的自動化品質提升提供新路徑。
深度分析
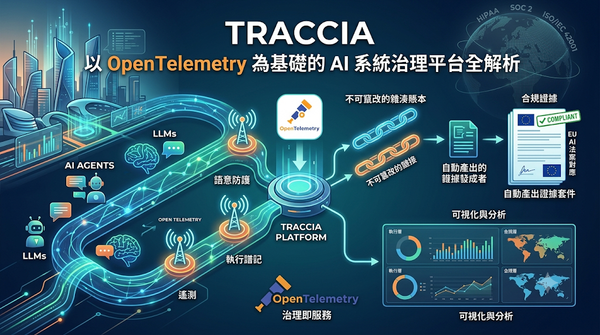
隨著大型語言模型與自主AI代理快速崛起,現有治理工具難以滿足EU AI法案的透明與問責要求。Traccia以OpenTelemetry為基礎,將遙測、語意防護與執行譜記整合至不可竄改的雜湊賬本,自動產出符合多條款的合規證據,縮短治理與合規的最後一哩路。

深度分析
本篇報導深入探討生成模型的控制機制,指出傳統的提示、指導尺度與屬性標籤(統稱旋鈕)只能在資料預先設定的「預算」內調整屬性,而大量未被旋鈕覆蓋的範圍只能透過示例(具體實例)來引導。研究提供了以訓練資料簡易審核預算的方法,並示範在影像與晶體結構兩個完全不同領域中,示例導向如何突破旋鈕的限制,實現更完整的屬性移動與更高的表現力。

速報
研究針對 28 場衝突向五大 AI 問答引擎提出 5,460 個問題,將回覆與已知事實比對。結果顯示,當可查證的資料稀薄時,模型更容易捏造、錯置或錯算資訊,且這類薄弱記錄容易被生成式引擎優化(GEO)操控,成為錯訊與假訊的溫床。分析 1,048 個來源網站後發現,GEO 已在實務中運作,且國家或黨派的數位介入正快速擴散。

速報
現有 AI 研究系統多集中於經驗驅動領域,缺乏對理論推導的支援。ReasFlow 推出端到端自主代理系統,透過內部驗證迴圈確保邏輯一致性,並結合自動化知識檢索與自我提升機制,將文獻合成、定理證明與論文撰寫整合在單一系統中。該系統能從極簡提示詞自主生成完整研究論文,且評分結果優於目前主流開源基準模型。