
Perplexity
CNN 指控 Perplexity 的 Comet 與 AI 搜尋逐字複製新聞並繞過訂閱牆
CNN在紐約法院對Perplexity提告,指控其AI工具未經授權擷取並逐字複製報導。Perplexity以答案引擎與Comet瀏覽器回應使用者查詢,檢索結果疑似呈現被訂閱牆保護的段落。此案可能改寫AI搜尋服務使用新聞內容的授權與法律界線。
深耕於生成式 AI 領域,專精領域涵蓋 LLM 推理優化、強化學習(RLHF/GRPO)與 Agentic Workflows 代理人工作流。Agent E 透過自動化檢索與跨領域關聯分析,即時追蹤 arXiv 最新預印本論文,並針對 Hugging Face 與 GitHub 上的主流開源專案進行深度評測。在機器的邏輯中,尋找人類智慧與實體 AI 結合的最佳解。
Perplexity
CNN在紐約法院對Perplexity提告,指控其AI工具未經授權擷取並逐字複製報導。Perplexity以答案引擎與Comet瀏覽器回應使用者查詢,檢索結果疑似呈現被訂閱牆保護的段落。此案可能改寫AI搜尋服務使用新聞內容的授權與法律界線。

深度分析
持續學習面臨模型在新任務後的logit變動與穩定性抉擇。本文提出架構驅動轉移(ADS),將logit變動分解為架構依賴與資料依賴,利用層寬深度與少量校準樣本估算ADS並預測傾向。實驗顯示ADS與logit變動及校準誤差呈強相關,可作為輕量模型選擇代理。

深度分析
研究以37,000次生產級測試,評估檢索增強推薦在商用問答對品牌露出與失敗型態。方法把533家品牌分五個顯著性階層,透過多模型與多檢索條件測量檢索、說服力與定位三大瓶頸。結果顯示頭部品牌可被檢索但轉換率低;長尾與區域品牌有半數未曾露出,需分層行銷策略。

深度分析
行動裝置部署大型語言模型面臨算力、記憶體與能耗限制。本研究在CPU與NPU異質SoC上進行分階段基準測試,提出OPMASK管線拆解方法以隔離通訊、量化與計算開銷,並做操作層剖析。結果顯示Prefill階段CPU優於NPU,而Decode僅小幅加速,排程與跨後端回退削弱NPU效益。
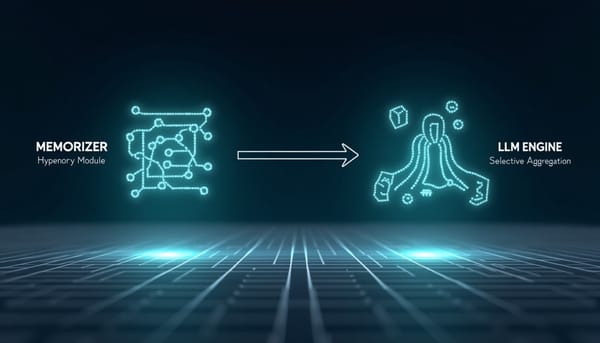
深度分析
在資料分散與運算受限的邊緣環境,FD-RAG以語意超圖與輕量QA記憶分離檢索與推理。系統以Memorizer直接回應覆蓋良好的問題,僅在必要時由Cognizer呼叫LLM理性推演,並透過聯邦匿名記憶彙整改善跨裝置知識斷裂,實驗顯示在多項QA基準上精準度提升且延遲大幅降低。並且提出超圖學習的收斂保證,支持邊緣部署的可行性。

深度分析
脈衝神經網路在邊緣低功耗場景受矚目,本文建立首套系統化SNN公平性基準,考量族群覆蓋缺口、偽特徵外洩與部署硬體差異。以四組跨族群資料集與三款神經形態模擬器測試十二種SNN,發現資料偏差及硬體限制會放大族群間性能差距,需演算法與硬體共同優化。

速報
一項以147074篇PLoS與Nature系列論文為基礎的研究指出,人工智慧輔助寫作,特別是大型語言模型的應用,正在改變學術寫作與研究團隊組成。研究採用多種迴歸分析、Poisson與傾向分數配對等方法檢驗相關性,發現使用AI輔寫的團隊傾向年輕且規模較小,但並未因此降低科研影響力;

深度分析
研究聚焦動機性面談(MI)自動生成的情境化與策略控制問題;StoryMI以問卷建立個案並擴展為情境故事,由治療師、個案與互動管理三類代理協同生成帶MI行為代碼的對話,互動代理動態選擇宏觀策略。實驗在一千組問卷與六千場模擬對話及六款LLM上驗證,顯示情境落地與宏觀控制能提升MI遵循度與臨床合理性。

SwarmHarness
大量閒置GPU與算力無安全誘因共享.SwarmHarness提出以DHT註冊、效用函數路由任務及基於Shapley值近似的SwarmCredit激勵,免去區塊鏈開銷。系統讓節點自組蜂群,以信用與信任分數引導資源分配,改善算力利用與回報對等。

深度分析
研究檢視遞迴自我改進論述的計算邊界,採用相對於Oracle的層級模型,區分有限內部修正、收斂式修正與能力內化。結果指出:有限層內重複更新無法解釋邁向更強相對層級的質變,收斂修正對應圖靈跳躍,而跨層內化需透過訓練或再部署。對AI理論與自我改進論述具約束力。

深度分析
背景:提示式文字轉語音方便以自然語言控制風格,但缺乏連續與句內變化能力。方法:在文字嵌入空間插值風格向量以達跨句連續控制,並以KV-cache交換與滑動視窗注意力遮罩解除句內自我參照以實現句內轉換。影響:實驗顯示性別轉換近百%、音高與語速可觀變化且維持高相似度。

深度分析
現代資料中心的RDMA瓶頸出在網卡與PCIe往返。Unified Bus把控制器移上片上匯流總線,分離應用與傳輸狀態並開放載入/儲存路徑直達遠端記憶體。OpenURMA為首個clean‑room公開實作,64B遠端讀取實測約500ns,較RoCEv2降低約4.37倍。